Automated Yield Data Cleaning and Calibration (AYDCC) is a process that uses algorithms and models to detect and correct errors in yield data, such as outliers, gaps, or biases. AYDCC can improve the quality and reliability of yield data, which can lead to better insights and recommendations for farmers.
Introduction to Yield Data
Yield data is one of the most important sources of information for farmers in the 21st century. It refers to the data collected from various farm machinery, such as combines, planters, and harvesters, that measure the quantity and quality of crops produced in a given field or area.
It holds immense importance for several reasons. Firstly, it aids farmers in making informed decisions. Armed with detailed yield data, farmers can fine-tune their practices to maximize productivity.
For instance, if a specific field consistently produces lower yields, farmers can investigate the underlying causes, such as soil health or irrigation issues, and take corrective measures.
Furthermore, it enables precision agriculture. By mapping variations in crop performance across their fields, farmers can tailor their input applications, such as fertilizers and pesticides, to specific areas. This targeted approach not only optimizes resource use but also reduces environmental impacts.
According to the Food and Agriculture Organization (FAO), global agricultural production needs to increase by 60% by 2050 to meet the growing demand for food. Yield data, through its role in enhancing crop productivity, is instrumental in achieving this target.
Furthermore, in Brazil, a soybean farmer used yield data along with soil sampling data to create variable-rate fertilizer maps for his fields. He applied different rates of fertilizer according to the soil fertility and yield potential of each zone.
He also used yield data to compare different soybean varieties and select the best ones for his conditions. As a result, he increased his average yield by 12% and reduced his fertilizer costs by 15%.
Similarly, in India, a rice farmer also used yield datasets along with weather data to adjust his irrigation schedule for his fields. He monitored the soil moisture levels and rainfall patterns using sensors and satellite imagery.

He also used it to compare different rice varieties and select the best ones for his conditions. As a result, he increased his average yield by 10% and reduced his water use by 20%.
Despite its benefits, yield data still faces some challenges in terms of its development and adoption. Some of these challenges are:
- Data quality: Its accuracy and reliability depends on the quality of the sensors, the calibration of the machinery, the data collection methods, and the data processing and analysis techniques. Poor data quality can lead to errors, biases, or inconsistencies that can affect the validity and usefulness of the data.
- Data access: The availability and affordability of yield data depend on the access to and ownership of the farm machinery, the sensors, the data storage devices, and the data platforms. Lack of access or ownership can limit the ability of farmers to collect, store, share, or use their own data.
- Data privacy: Its security and confidentiality depends on the protection and regulation of the data by the farmers, the machinery manufacturers, the data providers, and the data users. Lack of protection or regulation can expose the data to unauthorized or unethical use, such as theft, manipulation, or exploitation.
- Data literacy: The understanding and utilization of yield data depend on the skills and knowledge of the farmers, the extension agents, the advisors, and the researchers. Lack of skills or knowledge can hinder the ability of these actors to interpret, communicate, or apply the data effectively.

Therefore, to overcome these challenges and realize the full potential of yield data, it is important to cleaning and calibrate the yield data.
Introduction to yield data cleaning and calibration
Yield data are valuable sources of information for farmers and researchers who want to analyze crop performance, identify management zones, and optimize decision-making. However, it often require cleaning and calibration to ensure their reliability and accuracy.
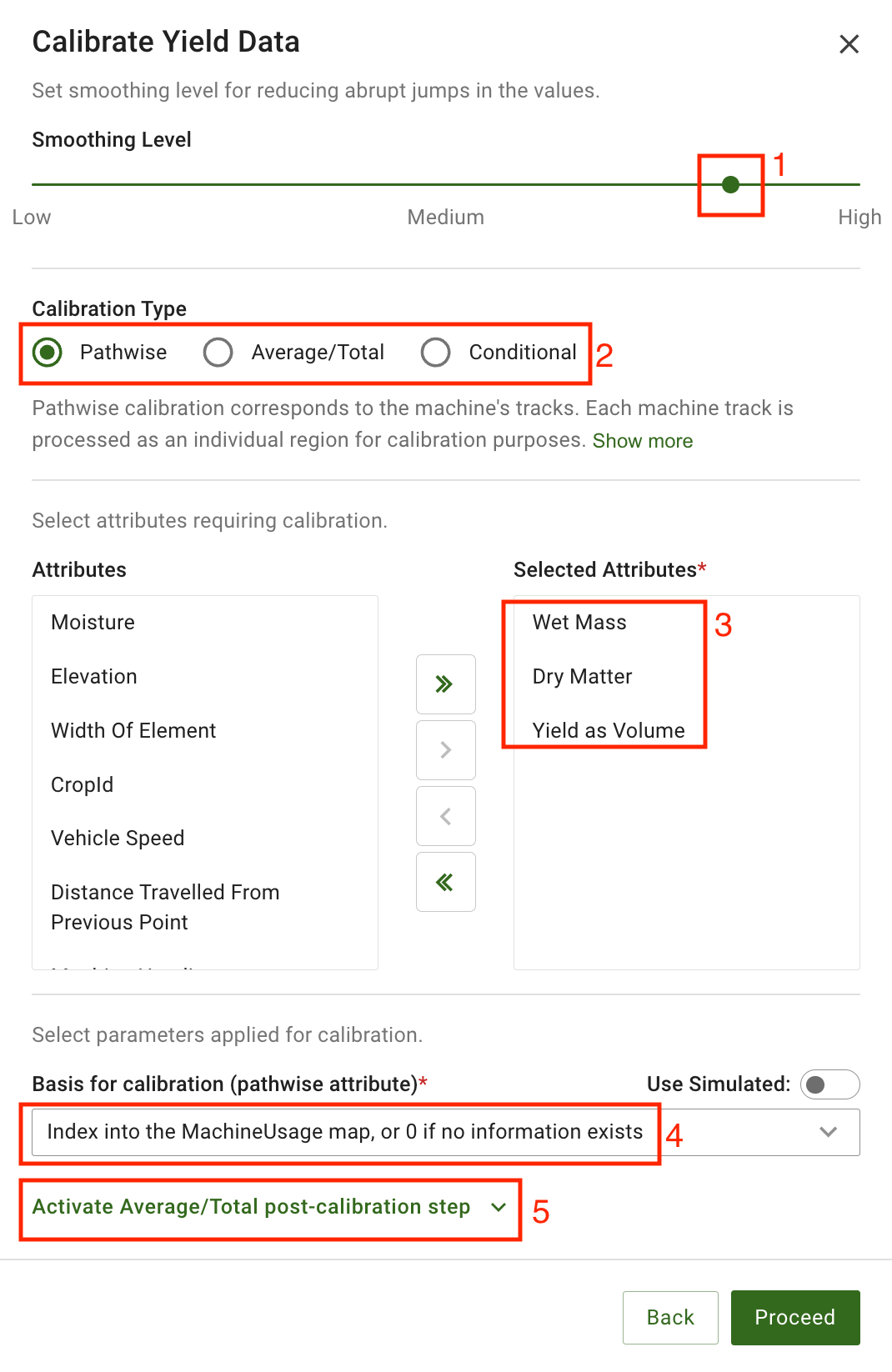
Calibrating the “YieldDataset” is a functionality that corrects the distribution of values in alignment with mathematical principles, enhancing the overall integrity of the data. It bolsters the quality of decision-making and renders the dataset valuable for further in-depth analysis.
GeoPard Yield Clean-Calibration Module
GeoPard made it possible to clean and correct yield datasets using its Yield Clean-Calibration module.
We’ve made it easier than ever to enhance the quality of your yield datasets, empowering farmers to make data-driven decisions that you can rely on.

After calibration and cleaning, the resulting yield dataset becomes homogeneous, without outliers or abrupt changes between neighboring geometries.
With our new module, you can:
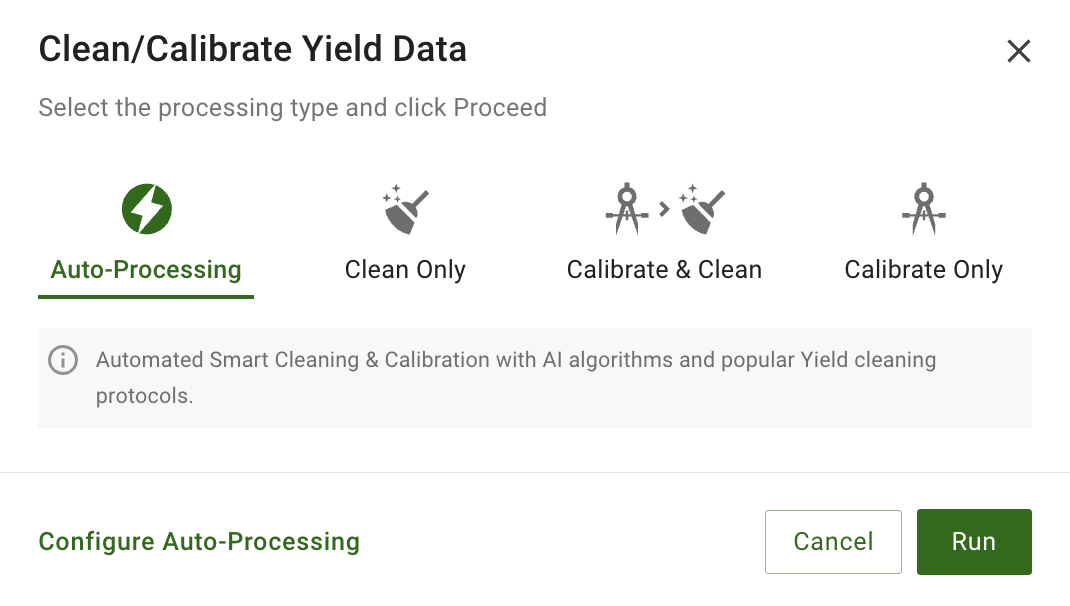
- Remove corrupted, overlapped, and subnormal data points
- Calibrate yield values across multiple machines
- Start calibration with just a few clicks (simplifying your user experience) or execute the associated GeoPad API endpoint







Some of the most common use cases of automated yield data cleaning and calibration include:
- Synchronizing data when multiple harvesters have worked either simultaneously or over several days, ensuring consistency.
- Making the dataset more homogeneous and accurate by smoothing out variations.
- Removing data noise and extraneous information that can cloud insights.
- Eliminating turnarounds or abnormal geometries, which may distort the actual patterns and trends in the field.
In the picture below, you can see a field where 15 harvesters worked at the same time. It shows how the original yield dataset and the improved dataset after calibration with GeoPard yield clean-calibration module look quite different and easy to understand.

Why is it important to clean and calibrate?
Yield data are collected by yield monitors and sensors that are attached to harvesters. These devices measure the mass flow rate and moisture content of the harvested crop, and use GPS coordinates to georeference the data.
However, these measurements are not always accurate or consistent, due to various factors that can affect the performance of the equipment or the crop conditions. Some of these factors are:
1. Equipment variations: Farm machinery, such as combines and harvesters, often have inherent variations that can lead to discrepancies in data collection. These variations might include differences in sensor sensitivity or machinery calibration.
For example, some yield monitors may use a linear relationship between voltage and mass flow rate, while others may use a nonlinear one. Some sensors may be more sensitive to dust or dirt than others. These variations can cause discrepancies in yield data across different machines or fields.


2. Environmental factors: Weather conditions, soil types, and topography play significant roles in crop yields. If not accounted for, these environmental factors can introduce noise and inaccuracies into yield data.
For instance, sandy soils or steep slopes may cause lower yields than loamy soils or flat terrains. Likewise, areas with higher crop density may have higher yields than areas with lower density.
3. Sensor inaccuracies: Sensors, despite their precision, are not infallible. They may drift over time, providing inaccurate readings if not regularly calibrated.
For example, a faulty load cell or a loose wiring may cause inaccurate mass flow rate readings. A dirty or damaged moisture sensor may give erroneous moisture content values. A wrong field name or ID entered by the operator may assign yield data to the wrong field file.
These factors can result in yield datasets that are noisy, erroneous, or inconsistent. If these data are not cleaned and calibrated properly, they can lead to misleading conclusions or decisions.
For example, using uncleaned yield data to create yield maps may result in false identification of high- or low-yielding areas within a field.

Using uncalibrated yield datasets to compare yields across fields or years may result in unfair or inaccurate comparisons. Using uncleaned or uncalibrated yield data to calculate nutrient balances or crop inputs may result in over- or under-application of fertilizers or pesticides.
Therefore, it is essential to perform yield data cleaning and calibration before using them for any analysis or decision-making purpose. Yield datasets cleaning is the process of removing or correcting any errors or noise in the raw yield data collected by the yield monitors and sensors.
Automated methods for cleaning and calibrating yield data
This is where automated data cleaning techniques come in handy. Automated data cleaning techniques are methods that can perform data cleaning tasks without or with minimal human intervention.
Automated data cleaning techniques can save time and resources, reduce human errors, and enhance the scalability and efficiency of data cleaning. Some of the common automated data cleaning techniques for yield data are:
1. Outlier Detection: Outliers are data points that deviate significantly from the norm. Automated algorithms can identify these anomalies by comparing data points to statistical measures such as mean, median, and standard deviation.
For example, if a yield dataset shows an exceptionally high harvest yield for a particular field, an outlier detection algorithm can flag it for further investigation.
2. Noise Reduction: Noise in yield data can arise from various sources, including environmental factors and sensor inaccuracies.
Automated noise reduction techniques, such as smoothing algorithms, filter out erratic fluctuations, making the data more stable and reliable. This helps in identifying true trends and patterns in the data.
3. Data Imputation: Missing data is a common issue in yield data sets. Data imputation techniques automatically estimate and fill in missing values based on patterns and relationships within the data.
For instance, if a sensor fails to record data for a specific time period, imputation methods can estimate the missing values based on adjacent data points.
Hence, automated data cleaning techniques serve as the gatekeepers of data quality, ensuring that yield datasets remain a reliable and valuable asset for farmers worldwide.
Furthermore, there are lots of handy tools and computer programs that can automatically clean and adjust yield data, and GeoPard is one of them. The GeoPard Yield Clean-Calibration Module, along with similar solutions, is super important for making sure the data is accurate and reliable.

Conclusion
Automated Yield Data Cleaning and Calibration (AYDCC) is essential in precision agriculture. It ensures the accuracy of crop data by removing errors and enhancing quality, enabling farmers to make informed decisions. AYDCC addresses data challenges and utilizes automated techniques for trustworthy results. Tools like GeoPard’s Yield Clean-Calibration Module simplify this process for farmers, contributing to efficient and productive farming practices.
Satellite Imagery