La detección inteligente de enfermedades en las hojas del tomate se sitúa en la confluencia de dos fuerzas poderosas que están transformando la agricultura mundial: el peso económico del cultivo del tomate y el rápido desarrollo de la tecnología de visión artificial. El tomate es el cultivo hortícola más extendido del mundo, con una producción que abarca más de 5 millones de hectáreas en más de 170 países.
Las pérdidas causadas únicamente por enfermedades foliares reducen significativamente la producción cada temporada, y la inspección visual convencional por parte de los trabajadores agrícolas es demasiado lenta, variable y costosa para implementarla a gran escala. La agricultura de precisión, impulsada por la IA, ofrece una mejor solución. Esta guía abarca todo el espectro de la detección inteligente de enfermedades foliares del tomate, desde la biología fundamental hasta las arquitecturas más avanzadas.
Por qué es importante el cultivo del tomate y la detección de enfermedades.
Tomate (Solanum lycopersicum) es el cultivo de hortalizas más investigado en fitopatología, y la justificación económica de ese enfoque es clara. La producción mundial de tomate alcanzó 186 millones de toneladas métricas en 2024, con la contribución de China 37% de la producción total.
Este cultivo abastece a las industrias de procesamiento de alimentos, los mercados de productos frescos y los huertos familiares en todos los continentes. Solo en Estados Unidos, el valor de la producción de tomates para el mercado de productos frescos en 2023 superó los miles de millones de dólares, según el Centro de Investigación de Comercialización Agrícola.
Las enfermedades foliares son la principal amenaza para la productividad del tomate. La Organización de las Naciones Unidas para la Alimentación y la Agricultura (FAO) estima que las enfermedades de las plantas representan aproximadamente 40% de pérdidas de cosechas a nivel mundial, lo que se traduce en enormes consecuencias para la seguridad alimentaria y la economía.
Las enfermedades fúngicas por sí solas causan pérdidas anuales por valor de $60 mil millones en todo el mundo. En el caso específico de los tomates, la mancha bacteriana en condiciones favorables para la enfermedad puede reducir los rendimientos en hasta 90%, lo que hace que el tiempo de detección y respuesta sea fundamental.

La identificación temprana y precisa de enfermedades es clave. Un agricultor que detecta el tizón temprano en su fase inicial de lesión puede controlarlo con la aplicación específica de fungicidas. Un agricultor que no lo detecta hasta que se produce una defoliación visible se enfrenta a pérdidas de rendimiento que ninguna intervención puede revertir por completo. Aquí es donde la inteligencia artificial, específicamente la detección inteligente de enfermedades en las hojas del tomate mediante aprendizaje profundo, cambia las reglas del juego.
El contexto más amplio respalda este cambio. El mercado global de IA en agricultura de precisión se valoró en $3.1 mil millones en 2024 y se prevé que alcance $12.7 mil millones para 2034 en un CAGR de 15,1% (Market.us, 2024). El monitoreo inteligente de enfermedades de los cultivos es uno de los segmentos de más rápido crecimiento dentro de esa expansión.
Enfermedades de las hojas del tomate: una visión general para la detección
Para que cualquier sistema de detección funcione, es necesario comprender con precisión qué es lo que se le pide que encuentre. Las hojas de tomate se ven afectadas por una amplia gama de patógenos, cada uno de los cuales deja huellas visuales distintivas, aunque a veces superpuestas.
1. Enfermedades comunes de las hojas del tomate y sus agentes causales
Tizón temprano, causada por el hongo Alternaria solani, Produce lesiones anulares concéntricas de color marrón oscuro en las hojas más viejas. Los anillos se asemejan a una diana, y el tejido muere y se torna amarillento alrededor de cada lesión.
Tizón tardío, causado por el oomiceto Phytophthora infestans —el mismo organismo responsable de la hambruna de la patata en Irlanda— produce manchas de color verde grisáceo empapadas de agua que se tornan marrones rápidamente en condiciones cálidas y húmedas. Se propaga con extrema rapidez y puede destruir un campo entero en cuestión de días.
Mancha foliar de Septoria Se presenta como pequeñas manchas circulares con bordes de color marrón oscuro y centros de color canela más claro. Por lo general, comienza en las hojas inferiores y avanza hacia arriba, causada por el hongo. Septoria lycopersici.
Mancha bacteriana, causado por Xanthomonas vesicatoria, Produce pequeñas manchas empapadas de agua que se vuelven marrones y angulares, a menudo rodeadas de halos amarillos. A diferencia de las manchas causadas por hongos, las lesiones bacterianas no responden a los tratamientos con fungicidas.
Moho de hoja, causado por Passalora fulva, Se manifiesta como manchas de color verde pálido o amarillo en la superficie superior de las hojas, con moho de color verde oliva a púrpura grisáceo en la parte inferior. Prospera en ambientes húmedos de invernadero.
Virus del mosaico del tomate (ToMV) Produce patrones moteados de color verde claro y oscuro en las hojas, a menudo con hojas rizadas y ampollas. La distribución irregular del color lo distingue de las deficiencias nutricionales.
Virus del rizado amarillo de la hoja del tomate (TYLCV), transmitida por la mosca blanca Bemisia tabaci, Provoca el rizado ascendente de los márgenes de las hojas, amarillamiento entre las nervaduras y un retraso severo del crecimiento. Es una de las enfermedades virales más dañinas económicamente en las regiones cálidas productoras de tomate en todo el mundo.
2. Síntomas de la enfermedad y el desafío de la detección fundamental
La identificación visual supone un reto importante incluso para los agrónomos capacitados. Los síntomas iniciales de diferentes enfermedades pueden ser prácticamente idénticos en una foto tomada con un teléfono inteligente. Tanto la septoriosis como la mancha bacteriana producen pequeñas lesiones redondas. El tizón temprano y el tizón tardío provocan la muerte del tejido tisular. Factores ambientales como la deficiencia de nitrógeno, el estrés por frío y la fitotoxicidad de los herbicidas pueden simular síntomas virales.
- Las condiciones de iluminación al capturar la imagen alteran drásticamente la apariencia del color y la textura de las lesiones, y las fotos sobreexpuestas borran los patrones de anillos que son fundamentales para la identificación temprana de la enfermedad.
- En una sola hoja pueden aparecer varias enfermedades simultáneamente, y los síntomas de un patógeno pueden superponerse visualmente a los de otro; un escenario que supone un reto tanto para los expertos humanos como para los modelos de IA.
- La progresión de la enfermedad modifica su apariencia con el tiempo, lo que significa que un modelo entrenado únicamente con lesiones en etapas avanzadas a menudo no detecta las etapas más tempranas y tratables de la infección.
- La complejidad del fondo en las imágenes de campo (suelo, otras hojas, fruta y equipos de riego) añade ruido visual que reduce la precisión de la clasificación en condiciones reales en comparación con las condiciones de laboratorio.
Estas no son meras complicaciones académicas. Influyen directamente en cómo deben crearse los conjuntos de datos de detección, cómo deben entrenarse los modelos y cómo deben validarse los sistemas de detección antes de su implementación.
Papel fundamental de la detección temprana de enfermedades en la gestión de cultivos.
La detección temprana no se trata simplemente de actuar con rapidez, sino de actuar cuando la acción aún es efectiva. Los fungicidas aplicados ante los primeros signos de lesiones de tizón temprano previenen la esporulación y la propagación lateral. Los mismos fungicidas aplicados después de la defoliación del dosel vegetal (30%) tienen escaso retorno económico.
- Rendimiento de los cultivos La protección es el beneficio más directo: los campos donde la enfermedad se detecta en los primeros 10 a 14 días desde la aparición de los síntomas muestran sistemáticamente pérdidas de rendimiento significativamente menores que aquellos donde la detección se retrasa dos semanas o más.
- Uso de pesticidas La reducción se logra mediante una sincronización precisa. En lugar de aplicar fungicidas según un calendario, los agricultores con capacidad de detección temprana pueden aplicarlos solo cuando se confirma un nivel umbral de infección, reduciendo el uso de productos químicos hasta en un 40-50%.
- Ahorro de costes Los costos se acumulan rápidamente a lo largo de la temporada de cultivo. Menos aplicaciones de pesticidas significan menos mano de obra, combustible y gastos en productos químicos. Para una explotación mediana de tomate que gestiona más de 50 hectáreas, estos ahorros son sustanciales.
- Objetivos de agricultura sostenible Se apoyan directamente. La reducción en la aplicación de pesticidas disminuye la escorrentía hacia los sistemas hídricos y reduce la presión de selección para cepas de patógenos resistentes.
- prevención de la propagación de enfermedades Protege no solo campos individuales, sino distritos agrícolas enteros. El tizón tardío, por ejemplo, produce esporas dispersadas por el viento que pueden infectar granjas vecinas a las pocas horas de su esporulación.
La lógica económica y agronómica es convincente: invertir en tecnología de detección temprana reduce drásticamente los costes posteriores del control de enfermedades.
Sánchez-Sánchez et al. (2024) estimaron que las enfermedades virales por sí solas reducen el valor de la producción mundial de tomate en un De 2 a 51 TP3T anualmente, una cifra que se traduce en pérdidas de miles de millones de dólares estadounidenses dada la magnitud del mercado mundial de este cultivo.
Incluso una modesta reducción de las pérdidas relacionadas con enfermedades gracias a la detección temprana mediante IA puede generar un retorno de la inversión en tecnología en una sola temporada de cultivo para los productores de tomate a gran escala.
Agricultura de precisión y sistemas inteligentes de monitoreo de enfermedades
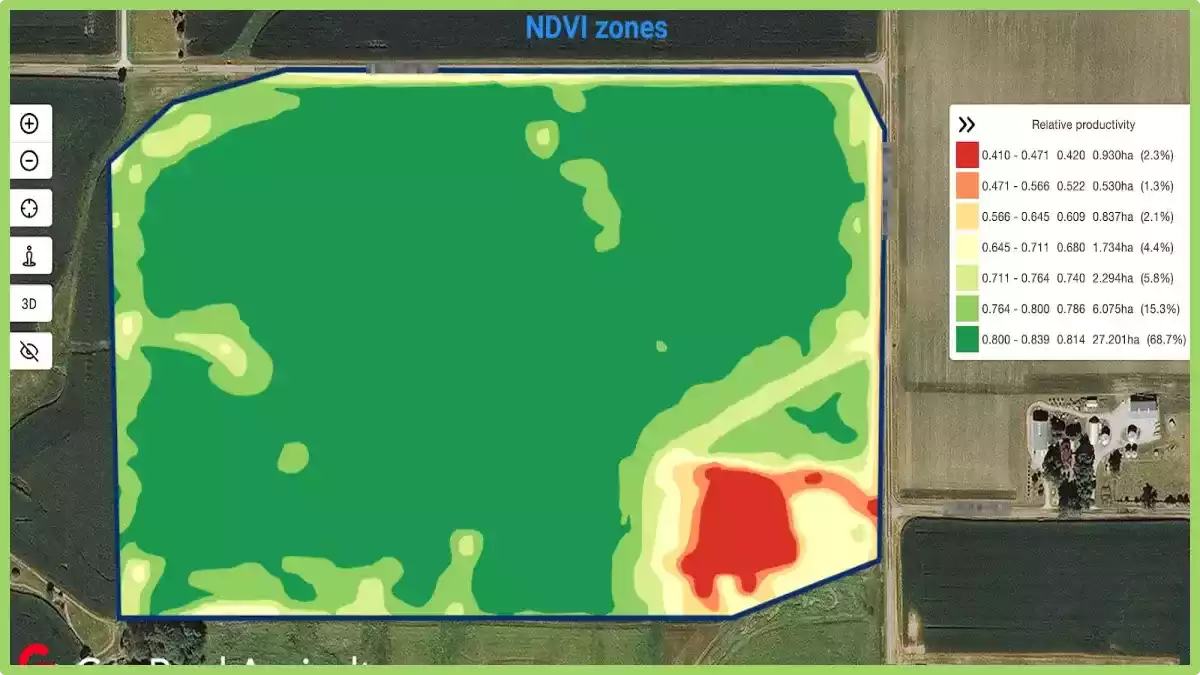
La agricultura de precisión consiste en tratar una explotación agrícola como un mosaico de zonas diferenciadas, en lugar de un campo uniforme. En vez de aplicar la misma cantidad de semillas, volumen de agua o dosis de fungicida a cada metro cuadrado, los sistemas de precisión utilizan datos en tiempo real para variar los insumos según las condiciones reales de cada lugar.
1. Conceptos básicos de la agricultura de precisión
La agricultura basada en datos se fundamenta en un ciclo continuo: sensores y sistemas de imagen recopilan datos de campo, el software los procesa e interpreta, y las herramientas de apoyo a la toma de decisiones traducen esa interpretación en recomendaciones prácticas. Para que el sistema genere valor, cada eslabón de esta cadena debe ser preciso.
La gestión inteligente de cultivos extiende esta lógica a las amenazas biológicas. En lugar de esperar a que los síntomas de la enfermedad se hagan evidentes o depender de recorridos de inspección semanales, un sistema de monitoreo inteligente detecta la enfermedad ante el primer signo visible o espectral y activa una alerta que especifica la ubicación, la identidad y la probable gravedad de la infección.
2. Tecnologías de monitoreo de enfermedades en la agricultura de precisión moderna
La imagen digital constituye la fuente de datos fundamental para la mayoría de los sistemas inteligentes de detección de enfermedades. Las cámaras RGB capturan la información de color visible para el ojo humano. Las cámaras multiespectrales capturan longitudes de onda más allá de la luz visible, incluyendo el infrarrojo cercano, lo que revela el estrés de la clorofila antes de que sea visible a simple vista.
Las cámaras hiperespectrales capturan cientos de bandas de longitud de onda estrechas y pueden detectar cambios bioquímicos a nivel molecular, aunque siguen siendo costosas para la mayoría de las aplicaciones agrícolas.

Los sensores terrestres y las redes de Internet de las Cosas (IoT) complementan la obtención de imágenes. Los sensores de temperatura y humedad colocados dentro de las copas de los cultivos proporcionan datos microclimáticos que indican cuándo se están desarrollando condiciones favorables para las enfermedades.
Un período prolongado de humedad en las hojas superior a 10 horas, combinado con temperaturas entre 18 y 22 °C, es una señal conocida que desencadena la aparición del tizón tardío; un sistema de IoT puede emitir una alerta de riesgo de enfermedad antes de que aparezca cualquier lesión.
Los drones y los vehículos aéreos no tripulados (VANT) aportan una dimensión espacial al monitoreo de enfermedades que las imágenes terrestres no pueden ofrecer. Un VANT equipado con una cámara multiespectral puede inspeccionar un campo de tomates de 10 hectáreas en menos de 30 minutos, generando un mapa georreferenciado de riesgo de enfermedades que muestra con precisión qué filas y zonas presentan señales tempranas de estrés.
Esto permite un tratamiento específico de las zonas de alto riesgo, en lugar de aplicaciones en todo el campo. Los sistemas agrícolas habilitados para IoT integran todos estos flujos de datos en una plataforma unificada, que envía las observaciones a nivel de campo a análisis basados en la nube o nodos de computación perimetral donde los algoritmos de clasificación de enfermedades se ejecutan prácticamente en tiempo real.
Aprendizaje profundo para la detección de enfermedades en las hojas de tomate
El aprendizaje profundo es una rama del aprendizaje automático en la que los algoritmos aprenden a extraer patrones directamente de los datos brutos —en este caso, imágenes— a través de capas jerárquicas de transformaciones matemáticas.
La principal ventaja sobre el aprendizaje automático clásico es que el aprendizaje profundo no requiere que un experto humano defina manualmente qué características (formas, texturas, gradientes de color) buscar en la imagen de una hoja enferma. El algoritmo aprende esas características a partir de ejemplos de entrenamiento.
1. Fundamentos del aprendizaje profundo para la clasificación de imágenes
En Red neuronal artificial (RNA) (un sistema computacional vagamente inspirado en las neuronas biológicas) procesa los datos de entrada a través de capas de nodos interconectados.
Cada conexión tiene un peso numérico que determina la influencia que la activación de un nodo ejerce sobre el siguiente. Entrenar la red implica ajustar esos pesos utilizando ejemplos etiquetados hasta que las predicciones de salida de la red coincidan con las etiquetas correctas con un margen de error mínimo.
A Red neuronal convolucional (CNN) (Una arquitectura de red neuronal especializada diseñada para datos de imagen) aplica operaciones matemáticas llamadas convoluciones a través de una imagen. Una convolución desplaza una pequeña ventana de filtro —normalmente de 3×3 o 5×5 píxeles— a través de la imagen y calcula una suma ponderada en cada posición, produciendo un mapa de características que captura patrones locales como bordes, texturas y gradientes de color.
Apilar múltiples capas convolucionales permite que la red aprenda características progresivamente más abstractas: bordes en las primeras capas, formas en las capas intermedias y patrones específicos de enfermedades en las capas más profundas.

Este aprendizaje jerárquico de características es precisamente lo que hace que las CNN sean tan eficaces para la detección de enfermedades en el tomate. El borde circular de una lesión, su gradiente de textura interna, el halo amarillento que la rodea: todas estas características se convierten en combinaciones que se pueden aprender a través de las capas de la red.
2. ¿Por qué el aprendizaje profundo supera a los métodos tradicionales?
El aprendizaje automático tradicional para la detección de enfermedades en plantas requería que expertos en la materia diseñaran manualmente características: extraían histogramas de color, calculaban descriptores de textura o medían parámetros de forma a partir de imágenes de hojas, para luego introducir esos datos en clasificadores como las máquinas de vectores de soporte (SVM). Este proceso era laborioso, dependía de la experiencia de expertos y era frágil cuando la apariencia de la enfermedad variaba con respecto a las condiciones de entrenamiento.
- El aprendizaje profundo realiza la extracción automática de características, aprendiendo directamente de los datos de píxeles sin necesidad de ingeniería manual de características, lo que elimina el cuello de botella de los descriptores definidos por expertos.
- La precisión de clasificación con aprendizaje profundo supera habitualmente los 95% y a menudo alcanza los 99%+ en conjuntos de datos de referencia, en comparación con una precisión de 80-88% para los enfoques tradicionales basados en SVM en los mismos datos.
- Los modelos de aprendizaje profundo se adaptan eficazmente a grandes conjuntos de datos. A medida que se añaden más imágenes de enfermedades etiquetadas, el rendimiento del modelo mejora, mientras que los métodos tradicionales se estancan cuando los conjuntos de características son fijos.
Lobna et al. (2024) entrenaron una red neuronal de cápsulas en un conjunto de datos a gran escala de 70.834 imágenes de hojas de tomate y logró una precisión de clasificación de 96.39% En múltiples categorías de enfermedades, superando a las redes neuronales convolucionales estándar (CNN) en los mismos datos.
Los conjuntos de datos amplios y diversos, combinados con arquitecturas optimizadas, ofrecen sistemáticamente niveles de precisión que superan los que se pueden lograr con los sistemas de visión artificial tradicionales.
Uso de la agricultura Geopard en la detección de enfermedades en campos reales
Geopard Agriculture crea precisamente esa capa. Su plataforma de monitoreo de precisión conecta la observación de campo, la identificación de enfermedades y el apoyo a la toma de decisiones en un único flujo de trabajo que cualquier agrónomo o agricultor puede operar desde un teléfono inteligente.
Lo que Geopard ofrece para el manejo de enfermedades del tomate.
El sistema de monitoreo inteligente de Geopard identifica las áreas de mayor valor en su campo para una inspección específica, en lugar de requerir una cobertura uniforme de cada hilera. Detecta automáticamente anomalías en la emergencia del cultivo y dirige el monitoreo a las zonas donde es más probable que se desarrollen problemas o estrés por enfermedades.
Esto aborda directamente el problema de la cobertura de campo que limita los programas de monitoreo manual en grandes explotaciones. La plataforma admite la detección y el registro de todas las principales categorías de amenazas en el campo relevantes para la producción de tomate:
- Reconocimiento de enfermedades fúngicas, incluyendo tizón temprano, tizón tardío, septoriosis y moho foliar: enfermedades en las que el momento de la detección determina de forma más directa el éxito de la intervención.
- Identificación de enfermedades bacterianas y virales, incluidos los síntomas de la mancha bacteriana y el virus del mosaico, con documentación fotográfica vinculada a coordenadas GPS para un mapeo preciso sobre el terreno.
- Detección de problemas de riego y fertilización, lo que permite a los equipos de exploración detectar síntomas de estrés abiótico que pueden imitar o agravar los síntomas de enfermedades en los cultivos de tomate.
- La identificación de malezas e insectos, junto con la detección de enfermedades, permite que una sola visita al campo genere una visión completa de las amenazas, en lugar de informes aislados de programas separados.
- El análisis de daños en las hojas y la toma de muestras de tejido permiten integrar el muestreo físico de laboratorio en el flujo de trabajo de exploración digital.
La planificación de zonas se integra en la fase de preparación del reconocimiento del terreno. Geopard convierte los datos brutos de sensores de campo y satélites en mapas de superficie con gradiente continuo que visualizan la heterogeneidad del terreno, lo que permite a los agrónomos definir zonas de manejo antes de que comience el reconocimiento. Los mapas de zonas y los datos del suelo están disponibles sin conexión a internet, lo cual es importante en fincas con cobertura celular irregular.
Ejecución móvil, generación de informes y alertas de emergencia
Todas las observaciones de campo se registran mediante la aplicación móvil Geopard. Los exploradores toman notas, fotografías y realizan observaciones georreferenciadas en tiempo real, y los registros de exploración completados se integran directamente en el panel de informes de la plataforma.

Los responsables de campo pueden ver qué amenazas se identificaron, dónde se encontraron, qué medidas se tomaron y qué zonas permanecen bajo vigilancia, sin necesidad de consolidar datos de formularios en papel o aplicaciones independientes.
El sistema de alerta de emergencia monitorea los patrones de propagación de enfermedades en la red de la plataforma y envía notificaciones cuando la presión de la enfermedad aumenta en su área. Esta función de alerta temprana amplía el período de detección efectiva más allá de lo que puede lograr el monitoreo interno de cualquier explotación agrícola, brindando a los agricultores tiempo suficiente para preparar respuestas preventivas antes de que la enfermedad llegue a sus campos.
El enfoque de Geopard demuestra la vía de integración práctica que los investigadores de agricultura de precisión describen en teoría: datos satelitales y de sensores que informan la priorización del monitoreo, herramientas móviles que permiten la captura de observaciones en tiempo real y la identificación de amenazas asistida por IA que respalda una toma de decisiones más rápida y específica a nivel de la explotación agrícola.
Preparación del conjunto de datos para la base del modelo de detección
La fiabilidad de un modelo de aprendizaje profundo depende de la calidad de los datos con los que fue entrenado. La preparación de conjuntos de datos para la detección de enfermedades en las hojas de tomate es un proceso de varias etapas que determina el rendimiento máximo de cualquier modelo en condiciones reales.
1. Fuentes de adquisición de imágenes
Las imágenes de campo capturadas en condiciones agrícolas reales —con iluminación variable, oclusión parcial, gotas de agua y fondo de tierra— representan el estándar de oro en cuanto a diversidad de conjuntos de datos, aunque son más difíciles y costosas de recopilar que las imágenes de entornos controlados.
Las imágenes tomadas con teléfonos inteligentes por los agricultores durante las labores de reconocimiento rutinarias se están convirtiendo cada vez más en una fuente de datos práctica que tiende un puente entre las condiciones de laboratorio y los escenarios de aplicación reales.
Los conjuntos de datos públicos han acelerado significativamente la investigación. Conjunto de datos de PlantVillage, desarrollado por la Universidad Estatal de Pensilvania, contiene más de 54.000 imágenes de hojas de plantas sanas y enfermas de 26 especies, incluidas 10 categorías de enfermedades del tomate.
Ha servido como base de entrenamiento para cientos de modelos publicados de detección de enfermedades del tomate y sigue siendo el conjunto de datos de referencia más utilizado en este campo.
2. Pasos de preprocesamiento de datos
Las imágenes sin procesar, obtenidas de diversas fuentes, contienen ruido, tamaños inconsistentes y diferencias en la calibración del color que pueden introducir patrones erróneos en el entrenamiento del modelo. El preprocesamiento estandariza los datos antes de que lleguen al modelo.
- El redimensionamiento de imágenes ajusta todas las imágenes a una resolución uniforme —normalmente 224×224 o 256×256 píxeles para las arquitecturas CNN—, lo que garantiza que las operaciones espaciales dentro de la red se apliquen de manera uniforme en todos los ejemplos de entrenamiento.
- La eliminación de ruido aplica filtros de suavizado, como el desenfoque gaussiano, para reducir el ruido del sensor y los artefactos de compresión JPEG que pueden engañar a las capas convolucionales sensibles a la textura.
- El aumento de datos expande artificialmente el conjunto de entrenamiento aplicando giros horizontales aleatorios, rotaciones, variaciones de color, ajustes de brillo y recortes aleatorios a las imágenes existentes. Esto enseña al modelo a reconocer patrones de enfermedades independientemente de la orientación de las hojas, el ángulo de iluminación o la composición de la imagen.
- La normalización reescala los valores de los píxeles desde su rango original de 0 a 255 a un rango más pequeño, generalmente de 0 a 1 o con media cero y varianza unitaria. Esto hace que el entrenamiento basado en gradientes sea numéricamente más estable y converja más rápidamente.
3. Anotación y etiquetado del conjunto de datos
Cada imagen en un conjunto de datos de aprendizaje supervisado debe llevar una etiqueta de referencia: a qué categoría de enfermedad pertenece o si la hoja está sana. Este etiquetado debe ser realizado o validado por fitopatólogos, no solo por generalistas agrícolas, ya que la superposición visual entre enfermedades hace que la anotación realizada por aficionados no sea fiable.
La anotación a nivel de clase para la clasificación de enfermedades es relativamente sencilla, pero la anotación de cuadros delimitadores para los modelos de detección de objetos —que marcan exactamente dónde aparece la lesión en la imagen— requiere mucho más tiempo y experiencia por imagen.
Arquitecturas de aprendizaje profundo utilizadas para la detección de enfermedades del tomate
La comunidad científica ha evaluado decenas de arquitecturas para la clasificación de enfermedades de las hojas de tomate. Comprender qué arquitecturas predominan y por qué ayuda a los profesionales a tomar decisiones informadas al implementar estos sistemas.
1. Redes neuronales convolucionales estándar
Los modelos CNN básicos para la clasificación de enfermedades siguen un patrón estándar: capas convolucionales para la extracción de características, capas de agrupación que reducen las dimensiones espaciales conservando las características dominantes y capas totalmente conectadas al final que asignan las características extraídas a las probabilidades de clase de la enfermedad.
Los primeros trabajos realizados con el conjunto de datos PlantVillage demostraron que incluso las CNN modestas con 5 a 7 capas podían alcanzar una precisión superior al 901% en imágenes limpias adquiridas en laboratorio.
2. Aprendizaje por transferencia con arquitecturas preentrenadas
Aprendizaje por transferencia La práctica de partir de un modelo preentrenado en un conjunto de datos general extenso y ajustarlo en un conjunto de datos específico del dominio transformó la investigación sobre la detección de enfermedades del tomate, al permitir entrenar modelos de alta precisión con conjuntos de datos agrícolas relativamente pequeños.
1. VGG16 y VGG19, Desarrollados por el Grupo de Geometría Visual de Oxford, utilizan 16 o 19 capas de pesos con convoluciones uniformes de 3×3. Siguen siendo métodos de referencia fiables para la clasificación de enfermedades del tomate, alcanzando normalmente una precisión de 94-97% tras el ajuste fino en conjuntos de datos de enfermedades.
2. ResNet La red residual (Residual Network) introdujo conexiones de salto que permiten que los gradientes fluyan directamente a través de las capas, resolviendo el problema del gradiente evanescente que anteriormente limitaba la profundidad de entrenamiento. ResNet50, ajustada con datos de enfermedades del tomate, alcanza consistentemente una precisión de 96-98% en estudios recientes.
3. DenseNet Amplía el concepto de conexión por salto conectando cada capa con cada capa subsiguiente en un bloque denso, maximizando la reutilización de características y produciendo modelos compactos con un sólido rendimiento de clasificación.
4. EfficientNet, desarrollado por Google Brain, escala el ancho, la profundidad y la resolución de la red simultáneamente utilizando un coeficiente compuesto. EfficientNetB0 con un módulo de atención logró Precisión del 99,39% sobre la clasificación de enfermedades de las plantas en la investigación publicada por González-Briones et al. (2025), con un rendimiento adecuado para la implementación de dispositivos periféricos.
5. MobileNet, Diseñada específicamente para dispositivos con recursos limitados, utiliza convoluciones separables en profundidad para reducir drásticamente los cálculos manteniendo una alta precisión, lo que la convierte en la arquitectura preferida para la implementación de IA en teléfonos inteligentes y dispositivos periféricos en la agricultura de precisión.
3. Modelos híbridos y avanzados
Las investigaciones más recientes han ido más allá de las redes neuronales convolucionales estándar (CNN) hacia arquitecturas que pueden capturar relaciones espaciales de mayor alcance en imágenes de hojas.
Vision Transformers (ViT) Las redes neuronales que aplican el mecanismo de atención Transformer, desarrollado originalmente para el procesamiento del lenguaje natural, a fragmentos de imágenes, han demostrado excelentes resultados en la detección de enfermedades de las plantas cuando se dispone de suficientes datos de entrenamiento.
A diferencia de las CNN, que procesan regiones locales de la imagen mediante convoluciones, las ViT aprenden relaciones entre todos los parches de la imagen simultáneamente, lo que les permite detectar patrones distribuidos espacialmente en toda una hoja.

Híbridos de CNN basados en atención Combinar la capacidad de extracción de características locales de las convoluciones con mecanismos de atención que permitan al modelo concentrar los recursos de procesamiento en las regiones de la imagen más relevantes para la enfermedad.
Se logró un marco ligero basado en redes siamesas para la detección de enfermedades del tomate. 96,97% de precisión en el subconjunto de tomates de Plant Village Con tan solo aproximadamente 2,96 millones de parámetros (Frontiers in Plant Science, 2025), se demuestra que la alta precisión y la eficiencia del hardware no son objetivos mutuamente excluyentes.
Modelos de aprendizaje de conjunto Se combinan las predicciones de múltiples arquitecturas entrenadas de forma independiente, promediándolas o mediante votación, para obtener una predicción final más robusta que la de cualquier modelo individual. Wu et al. (2024) aplicaron ResNet50 con técnicas de aumento de características para lograr un mejor rendimiento de clasificación mediante este enfoque.
Abdullah et al. (Agronomía, 2024) compararon YOLOv8s, YOLOv5 y Faster R-CNN para detectar hojas de tomate enfermas y encontraron que YOLOv8s logró una precisión media promedio (mAP) de 92.5%, superando a YOLOv5 con 89,1% y a Faster R-CNN con 77,5%, al tiempo que demuestra una mayor velocidad de inferencia y un menor tamaño del modelo.
Para aplicaciones de detección en tiempo real sobre el terreno, los modelos de la clase YOLOv8 ofrecen el mejor equilibrio entre precisión y velocidad de procesamiento, lo que los hace idóneos para su despliegue en drones o dispositivos periféricos.
Marco inteligente de detección de enfermedades
Un sistema inteligente y desplegable para la detección de enfermedades es más que un modelo entrenado. Es un proceso integral que abarca desde la captura de imágenes sin procesar hasta recomendaciones prácticas para el manejo de enfermedades.
1. Arquitectura del sistema
El proceso principal consta de cinco etapas secuenciales, cada una de las cuales transforma los datos antes de pasarlos a la siguiente.
1. La entrada de imágenes acepta imágenes de hojas sin procesar desde cualquier fuente de captura: un teléfono inteligente de campo, una cámara montada en un UAV o una cámara fija en el dosel de un invernadero. Los módulos de procesamiento de entrada validan la resolución de la imagen y marcan las capturas borrosas o inutilizables antes de que ingresen al proceso.
2. La etapa de preprocesamiento aplica los pasos de normalización, redimensionamiento y mejora de la calidad descritos en la Sección 6.2, asegurando que la entrada se ajuste al formato esperado por el modelo entrenado.
3. La extracción de características procesa la imagen preprocesada a través de las capas convolucionales del modelo de aprendizaje profundo entrenado. En esta etapa, el modelo transforma los datos de píxeles sin procesar en una representación numérica compacta (un vector de características) que codifica las características visuales de la hoja relevantes para la enfermedad.
4. La clasificación de enfermedades aplica las capas totalmente conectadas y la función de salida softmax al vector de características, calculando una puntuación de probabilidad para cada categoría de enfermedad. La categoría con la mayor probabilidad se convierte en el diagnóstico previsto.
5. El resultado del sistema de apoyo a la toma de decisiones traduce el resultado de la clasificación en una recomendación práctica: el nombre de la enfermedad identificada, el nivel de confianza, la acción de manejo sugerida (fungicida específico, agente de biocontrol, eliminación de las plantas afectadas) y los datos de ubicación georreferenciada si la imagen fue capturada por un dispositivo equipado con GPS.
2. Flujo de trabajo de un sistema de detección completo en la práctica
En una implementación real, un agricultor abre una aplicación móvil y fotografía una hoja afectada. La imagen se envía a un servidor en la nube que ejecuta el modelo de detección o se procesa localmente en el dispositivo mediante un modelo de borde comprimido.
En cuestión de segundos, la aplicación devuelve un diagnóstico: “Tizón temprano — 94% confianza. Acción recomendada: Aplicar fungicida a base de mancozeb a razón de 1,5 kg/ha en la zona afectada.
”Supervise las plantas vecinas durante los próximos 5 días”. El resultado georreferenciado se registra en el mapa digital de salud de la granja y, si la misma enfermedad aparece en varias zonas, el sistema activa una alerta de riesgo elevado para todo el bloque de campo.
Demilie (2024), revisando 161 publicaciones En la detección de enfermedades de las plantas basada en aprendizaje profundo, se descubrió que el tomate era el cultivo más investigado en todos los estudios, lo que representa 39% de todas las publicaciones — más del doble de la cobertura del segundo cultivo más estudiado (arroz en 16%), lo que confirma la singular confluencia de importancia económica y vulnerabilidad a las enfermedades que presenta este cultivo.
La madurez de la investigación sobre la detección de enfermedades del tomate permite a los profesionales acceder a una amplia gama de arquitecturas validadas y modelos preentrenados, en lugar de tener que construirlos desde cero.
Métricas de evaluación del desempeño
Elegir la métrica de evaluación adecuada es tan importante como elegir la arquitectura adecuada, sobre todo para la detección de enfermedades, donde los falsos negativos (no detectar una enfermedad real) conllevan costes diferentes a los de los falsos positivos (identificar erróneamente una hoja sana como enferma).
Exactitud Mide la proporción de predicciones correctas. Es la métrica que se suele reportar, pero puede resultar engañosa cuando las clases de enfermedades están desequilibradas: un modelo que siempre predice "sano" en un conjunto de datos con 90% imágenes sanas alcanza la precisión de 90%, pero resulta completamente inútil para la detección de enfermedades.
Precisión Mide qué fracción de las detecciones de la enfermedad son casos positivos reales, registrando la tasa de falsas alarmas. Su alta precisión implica que el modelo rara vez genera recomendaciones de tratamiento innecesarias.
Recuerdo (Sensibilidad) Mide qué fracción de las plantas enfermas reales se identifican correctamente. Una alta sensibilidad significa que el modelo rara vez pasa por alto infecciones reales, la métrica más importante para el manejo de enfermedades.
Puntuación F1 Es la media armónica de precisión y exhaustividad, que proporciona una medida única y equilibrada que penaliza a los modelos que sacrifican una por la otra. Es la métrica preferida cuando tanto los falsos positivos como los falsos negativos conllevan costes significativos.
Especificidad Mide la precisión con la que el modelo identifica las hojas verdaderamente sanas como sanas, lo cual es importante para evitar la aplicación innecesaria de pesticidas en cultivos libres de enfermedades.
En Matriz de confusión Muestra el desglose completo de las predicciones en todas las clases, revelando qué pares de enfermedades se confunden con mayor frecuencia, información fundamental para refinar los datos de entrenamiento o la arquitectura del modelo.
En ROC-AUC (Curva característica de funcionamiento del receptor: área bajo la curva) Mide la capacidad de discriminación general del modelo en todos los umbrales de clasificación, donde un valor de 1,0 representa una discriminación perfecta y 0,5 representa un rendimiento aleatorio.
Detección en tiempo real de enfermedades del tomate: Implementación
Trasladar un modelo de alta precisión de un cuaderno de investigación a un sistema de producción en laboratorio requiere resolver un conjunto de problemas diferente al del entrenamiento del modelo. Los entornos de implementación presentan limitaciones de hardware, conectividad y requisitos de latencia que condicionan la elección de la arquitectura y la infraestructura.
1. Aplicaciones para teléfonos inteligentes para el diagnóstico móvil de enfermedades
Las aplicaciones para teléfonos inteligentes representan la vía de implementación más accesible para los pequeños y medianos agricultores. Las aplicaciones basadas en los modelos MobileNet o EfficientNet-Lite realizan la inferencia completamente en el dispositivo, sin necesidad de conexión a internet en el momento de la captura.
El modelo de mayor precisión resulta inútil en la agricultura de precisión a menos que pueda funcionar en el dispositivo que el agricultor ya lleva en el bolsillo.
Esto es de suma importancia para las explotaciones agrícolas en zonas rurales o con escasa conectividad. El agricultor fotografía una hoja sospechosa, recibe una predicción de enfermedad en 1-3 segundos y registra el resultado en una base de datos que recopila información sobre la salud de toda la explotación durante la temporada de cultivo.
2. Implementación de IA en el borde: inferencia en el dispositivo
IA de borde (Ejecutar la inferencia de IA directamente en el hardware ubicado en el punto de recolección de datos en lugar de enviar los datos a un servidor remoto) resuelve los problemas de latencia y conectividad de la detección basada en la nube. Los dispositivos periféricos dedicados, como la serie NVIDIA Jetson o los aceleradores Coral TPU de Google, pueden ejecutar modelos CNN comprimidos a más de 30 fotogramas por segundo, lo que permite el monitoreo continuo de hojas en tiempo real desde cámaras fijas montadas en rieles de invernaderos o estructuras de riego de campo.
Las técnicas de compresión de modelos —cuantización (reducción de la precisión numérica de los pesos del modelo), poda (eliminación de conexiones de red de baja importancia) y destilación del conocimiento (entrenamiento de un modelo pequeño para imitar uno grande)— hacen esto posible sin sacrificar una precisión aceptable.
3. Sistemas de monitoreo basados en drones para la vigilancia de explotaciones agrícolas a gran escala.
En explotaciones agrícolas de más de 20-30 hectáreas, la inspección a nivel del suelo no proporciona la cobertura espacial necesaria para detectar brotes de enfermedades antes de que se propaguen. Los sistemas de vehículos aéreos no tripulados (UAV) equipados con cámaras multiespectrales capturan indicadores de estrés fitosanitario a nivel de toda la parcela.
Las imágenes capturadas se envían a un procesador periférico integrado o se transmiten a una estación terrestre, donde el modelo de detección identifica las zonas infectadas y genera un mapa georreferenciado superpuesto a los registros digitales de las parcelas de la granja.
Esto supone un cambio en la gestión de la enfermedad, pasando de un enfoque reactivo (responder después de que los síntomas se hagan evidentes) a uno espacialmente proactivo (responder a coordenadas específicas del terreno donde se detecta un estrés temprano).
Desafíos en la detección de enfermedades basada en aprendizaje profundo
El sector ha experimentado un progreso notable, pero una evaluación honesta de los retos que aún quedan impide un exceso de confianza en las decisiones de implementación.
Conjuntos de datos de campo limitados Sigue siendo el problema más generalizado. La mayoría de los modelos de alta precisión se entrenan y evalúan en PlantVillage, que utiliza imágenes de hojas individuales con iluminación controlada sobre fondos limpios. El rendimiento en condiciones reales de campo disminuye significativamente cuando los mismos modelos se enfrentan a imágenes complejas con múltiples elementos tomadas bajo condiciones de iluminación variables.
Variaciones en las condiciones de iluminación — La luz solar directa provoca reflejos especulares en la superficie de las hojas, la luz difusa en días nublados aplana las señales de textura o las sombras proyectadas por el follaje de los cultivos alteran el color y la textura aparentes de las lesiones de manera que pueden degradar la clasificación entre 5 y 15 puntos porcentuales en comparación con las condiciones controladas.
Complejidad del fondo En las imágenes de campo, la inclusión de información visual irrelevante introduce elementos del suelo, el mantillo, las líneas de riego por goteo, la fruta y otras hojas pueden aparecer en el mismo fotograma que una hoja enferma, y los modelos que no han sido entrenados específicamente para fondos complejos suelen confundir los elementos del fondo con las características de la enfermedad.
Enfermedades múltiples Una sola hoja presenta un desafío de clasificación que la mayoría de los modelos de etiqueta única no están diseñados para manejar. Una hoja que expresa simultáneamente mancha bacteriana y tizón temprano requiere capacidad de clasificación multietiqueta, lo que aumenta la complejidad del entrenamiento y los requisitos de anotación del conjunto de datos.
Desequilibrio de clases En los conjuntos de datos de entrenamiento, donde hay muchas más imágenes de enfermedades comunes como el tizón temprano que de enfermedades raras como el virus del mosaico, los modelos tienden a confiar demasiado en las clases frecuentes y a ser poco fiables para las menos representadas.
Interpretación del modelo Esto representa una barrera importante para la confianza a nivel de explotación agrícola. Cuando un modelo clasifica una hoja como enferma con un nivel de confianza del 971%, la mayoría de los agricultores y agrónomos quieren comprender qué características visuales llevaron a esa decisión antes de actuar según la recomendación.
Avances recientes en la detección inteligente de enfermedades
La frontera de la investigación avanza simultáneamente en múltiples frentes, abordando diferentes aspectos del desafío descrito anteriormente.
1. Inteligencia Artificial Explicable (XAI) Las herramientas —en particular Grad-CAM (Mapeo de Activación de Clases Ponderado por Gradiente), que produce superposiciones de mapas de calor que muestran en qué regiones de una imagen de hoja se centró el modelo al tomar una decisión— abordan directamente el problema de la interpretabilidad.
Una visualización de Grad-CAM que muestra la atención del modelo concentrada en un anillo de lesión oscuro proporciona una forma de justificación que los agrónomos pueden evaluar y en la que pueden confiar.
2. Vision Transformers (ViT) Sigue ganando terreno en la detección de enfermedades del tomate a medida que mejoran las estrategias de preentrenamiento y disminuyen los requisitos de datos para el ajuste fino de ViT.
Su capacidad para capturar patrones globales a nivel de hoja, en lugar de características puramente locales, las hace particularmente prometedoras para detectar enfermedades virales que afectan la distribución de toda la superficie de la hoja en lugar de producir lesiones localizadas.
3. Aprendizaje federado Aborda el problema de los conjuntos de datos de campo al permitir que los modelos se entrenen de forma colaborativa en múltiples explotaciones agrícolas sin centralizar los datos confidenciales.
Cada granja entrena un modelo local con sus propias imágenes, y solo se comparten las actualizaciones de los parámetros del modelo (no las imágenes en sí) para mejorar un modelo global central. Esto preserva la privacidad de los datos de los agricultores al tiempo que amplía considerablemente la diversidad de los datos de entrenamiento.
La gestión de enfermedades de precisión no se definirá por la exactitud de un solo modelo, sino por la inteligencia del sistema que conecta la detección, la decisión y la acción.
4. Aprendizaje autosupervisado El sistema preentrena los modelos con grandes colecciones de imágenes de plantas sin etiquetar para aprender representaciones visuales generales, y luego los ajusta con pequeños conjuntos de datos de enfermedades etiquetadas. Esto reduce la carga de anotación y permite desarrollar modelos de alta calidad para categorías de enfermedades donde los ejemplos etiquetados son escasos.
5. Detección multimodal de enfermedades Integra datos de imágenes de hojas con lecturas de sensores espectrales, datos de estaciones meteorológicas y registros históricos de enfermedades en una entrada de modelo unificada. La combinación de datos visuales y ambientales puede mejorar el rendimiento de la detección más allá de lo que permiten los datos de imagen por sí solos, especialmente para enfermedades cuyos síntomas visuales están precedidos por cambios bioquímicos detectables en firmas espectrales.
Direcciones futuras de la investigación: lo que aún necesita el campo
La transición de modelos de investigación de alta precisión a una implementación fiable a nivel de explotación agrícola requiere un trabajo concentrado en varios frentes.
Validación de la implementación en el mundo real Es necesario abarcar diversas geografías y sistemas agrícolas, y no solo los parámetros de referencia de PlantVillage, para caracterizar honestamente la brecha de rendimiento entre la detección en condiciones controladas y en condiciones de campo.
Detección robusta a nivel de campo Se requerirán conjuntos de datos de campo diseñados específicamente para este fin, recopilados a lo largo de varias temporadas de cultivo, en varios países, con documentación sistemática de las condiciones meteorológicas en el momento de la captura de las imágenes.
Integración con IoT e infraestructura de agricultura inteligente — Conectar las alertas de detección de enfermedades directamente con los sistemas automatizados de riego y fertirrigación, las plataformas de pulverización con drones y el software de gestión agrícola — cerrará el círculo entre la detección y la acción.
Pronóstico predictivo de enfermedades, La combinación de los datos actuales de detección de enfermedades con los modelos de pronóstico meteorológico y los patrones históricos de propagación de enfermedades, cambiará el paradigma de la detección reactiva a la gestión anticipatoria: recomendar medidas preventivas antes de que aparezcan los síntomas.
Sistemas agrícolas autónomos — Las flotas de vehículos aéreos no tripulados (UAV) que realizan vigilancia continua sobre el terreno, señalan zonas afectadas por enfermedades y se coordinan con unidades de pulverización automatizadas sin intervención humana representan el horizonte hacia el que se dirige la tecnología actual de agricultura de precisión.
Conclusión
La detección inteligente de enfermedades en las hojas de tomate mediante aprendizaje profundo ya no es una tecnología experimental. Se trata de una aplicación madura y validada, con un creciente número de estudios revisados por pares que confirman su capacidad para identificar enfermedades del tomate con precisión, rapidez y a un coste accesible para los agricultores. Desde modelos CNN básicos entrenados con el conjunto de datos PlantVillage hasta arquitecturas híbridas con mecanismos de atención que alcanzan una precisión superior al 991%, la capacidad técnica actual supera la infraestructura de implementación disponible para la mayoría de las explotaciones agrícolas.
El camino a seguir es claro. Los sistemas de agricultura de precisión que integran la detección de enfermedades basada en imágenes con redes de sensores IoT, vigilancia con UAV y modelos meteorológicos predictivos definirán la producción competitiva de tomate en esta década. El mercado de la IA en la agricultura de precisión está creciendo a un ritmo acelerado. CAGR de 15,1% hacia $12.7 mil millones para 2034 Esto indica que dicha inversión ya está en marcha a gran escala.
Agricultura de precisión